Python Automated Jobs Scraping Bot
Description
Getting too tired from searching for jobs manually and going around Perth CBD to give people my resume during my first summmer break in Australia, I developed a jobs scraping bot to automate the process of looking for jobs and internships.
This project help me applied the theoretical knowledge that I learned from the Python unit(CITS1401) at UWA during my first semester into practical tools.
Overview
The simple script use BeautifulSoup and requests module to gather information includes: job's title, position, company's name, location, salary, level and links to the jobs all store within a csv file. All resources are on my github: https://github.com/namhai2307/Automated-jobs-scraping-bot.
Scope: Automatically gather jobs description and store them in an excel file so I can browse in one go instead of manually clicking on every single one. Use pandas and Matplotlib to perform analysis and visualization on the collected data sheet
Result preview: List of 550 automation engineering jobs
Presentation
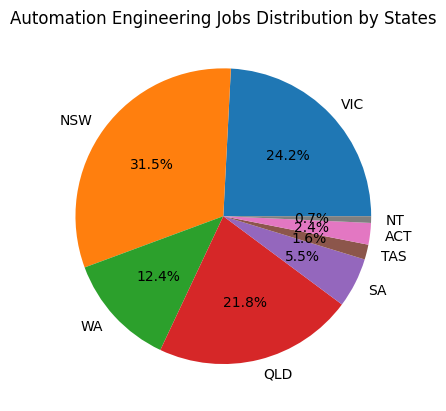
Using Matplotlib to analyze the location data, we can see that according to Seek, NSW is by far, the state with the leading number of automation engineering jobs available.
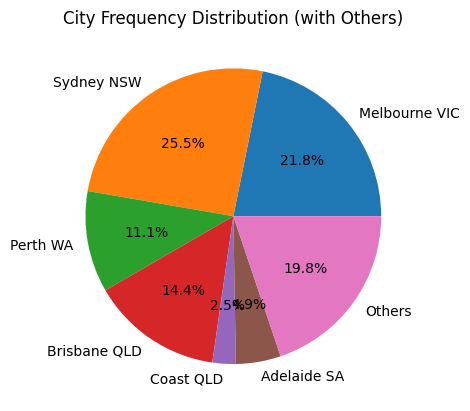
Not surprisingly, Sydney have the most automation engineering jobs. The total number of jobs in less major cities was actually greater than that of Perth, Adelaide and Brisbane.
The Boring Part:
Importing relevant libraries and define the data frame:
#importing libraries
from bs4 import BeautifulSoup, element
import requests
import pandas as pd
#define the data frame
data = {
"links": [],
"name": [],
"company": [],
"location":[],
"position": [],
"salary": [],
"level": []
}
Defines the main function and interacting with the web:
def filter(soup, lst):
if isinstance(soup, element.Tag):
name = soup.text
lst.append(name)
elif not isinstance(soup, element.Tag):
lst.append("N/A")
else:
lst.append("N/A")
Extracting data from each job card and storing them in respective lists:
Noted that the class attribute of tags are changed regulary, you might need to change the class name if you planning to use my code.
def extract(url):
respone = requests.get(url)
soup = BeautifulSoup(respone.text, "html.parser")
cards = soup.find_all('div', '_1ungv2r0 _1viagsn4z _1viagsn4x')
for card in cards:
link = card.find('a')
link = link.get("href")
if link != None:
data["links"].append("https://www.seek.com.au"+str(link))
#recursion function to go to the next page
next_card = soup.find('li', '_1ungv2r0 _1viagsnbb _1viagsnb0 _1viagsnx')
while isinstance(next_card, element.Tag):
n_link = next_card.find('a').get('href')
return extract("https://www.seek.com.au"+str(n_link))
#extract detail data
for i in data["links"]:
#extract raw html as text format
jobs = requests.get(i)
jobs_soup = BeautifulSoup(jobs.text, "html.parser")
job_name = jobs_soup.find("h1", attrs={"class": "_1ungv2r0 _1viagsn4z _3h66av0 _3h66avl _1708b944 _3h66avs _3h66av21"})
job_company = jobs_soup.find('span', attrs={"class": '_1ungv2r0 _1viagsn4z _1viagsni7 _3h66av0 _3h66av1 _3h66av21 _1708b944 _3h66ava'})
job_details = jobs_soup.find_all("div", attrs={"class": "_1ungv2r0 _1viagsn5b _1viagsnh7 _1viagsngr _157hsn62d"})
##
filter(job_name, data["name"])
##
filter(job_company, data["company"])
##
while len(job_details) < 5:
job_details.append("N/A")
##
filter(job_details[1], data["location"])
##
filter(job_details[2], data["position"])
##
filter(job_details[3], data["level"])
##
filter(job_details[4], data["salary"])
Using pandas to import the data frame into a csv file:
url = "https://www.seek.com.au/automation-engineer-jobs/in-All-Australia"
extract(url)
df = pd.DataFrame(data)
df
df.to_csv("job_data2.csv", index = False)
Result discussion:
Comparing the result from the bot to data from Engineers Australia on percentages of engineering jobs by region, I manage to a very close result:
- According to the second graph, approximately 77.7% of engineering jobs were located in the eight capital cities. Similarly, Engineers Australia reported that in June 2024, 77.1% of all engineering job advertisements were concentrated in the state capitals (page 12).
- The total percentages of jobs in NSW, QLD, Victoria and WA shown in the first graph was 89.9%, while Engineers Australia survey showed 88% of jobs in these 4 states combined (page 5).
- Fun fact: Engineers Australia also used Seek to gather data for their survey citation here




